Animating the Architect: An Origen Story Experiment

For my first published generative AI video experiment, I thought it would be fun to try and bring to life the Antoni Gaudí quote that inspired the name Origen Story. Gaudí's work merging biomorphic forms with modernisme architecture is a constant source of inspiration for me in Barcelona, and I wanted to capture some of that awe.
The result is a 40-second video where an AI-generated Gaudí speaks in Catalan about his architectural philosophy while the camera moves through animated versions of his works. But getting there meant pushing against the current limitations of AI tools in three key areas:
- Generating audio in lesser-known languages: Gaudí spoke Catalan and was a fierce advocate for his language and culture. He unabashedly spoke it in public even after it was prohibited and was imprisoned for doing so. The voice generation tools are impressive with English right now, but I wanted to see how voice generation and lip syncing would handle a language with far less training data.
- Creating a consistent historical figure: The Origen Story ethics code is clear about needing consent from private individuals to portray them using generative AI. A different standard typically applies to public figures, as there are legitimate educational reasons to portray historical figures. This is admittedly a tricky area, and I wanted to find where my personal line was in creating a visual style that would portray a public figure without confusing the historical record.
- One-shot creation: Most generative AI video produces 5 to 10 second clips using a generated image and then prompting the action. Increasingly, models like Kling use start and end images that allow you to stitch shots together to create longer shots or complex "oner" camera movements that would be difficult if not impossible in the real world. I wanted to play with different transitions and movements to see what worked with this approach.
Before diving into how I tackled these challenges, I should note that this is very much an experiment. For the past year, I've been iterating (and often failing) mostly in private. While that's been a valuable learning experience, I realize it doesn't help anyone if the work never sees the light of day. So I'm embracing the imperfect and sharing the process here, hoping we can figure this out together.
Step 1: Finding Gaudí's Voice
To create Gaudí's voice, my first stop was Matxa, a model developed by Project AINA at the Barcelona Supercomputing Center. It offers multiple Catalan dialects, but only two voices (male and female). The male voice was too young for my needs, so I tried ElevenLabs and was pleasantly surprised at the quality of the Catalan voices on offer. I was able to choose an age-appropriate voice, add pauses and breath, and get close to the sound I was after.
I ran the voice by a Catalan friend of mine, and while he thought it sounded good, he noted it was a VERY Barcelona accent. Gaudí was originally from Reus near Tarragona. If I wanted a truly accurate voice for Gaudí, it would probably require a voice performance from an actor. For this experiment, a very Barcelona Catalan accent would have to be good enough.
Step 2: Creating Gaudí
With the voice ready, I turned to the visual challenge: creating a consistent representation of Gaudí himself. One of the most challenging aspects of generative AI is creating consistency across characters, styles, and objects. Wrangling consistency out of these models is done by either using reference visuals or training a Low-Rank Adaptation (LoRA). The latter is considered more precise, but it's also more time consuming. In creating an AI rendering of Gaudí, I wanted to explore both approaches and see which worked best in different situations.
To understand how LoRAs work, it's worth taking a slight detour to explain another generative AI concept: latent space.
The latent space is the AI model's multidimensional map of everything it has learned. I've heard analogies where latent space is described as a map with neighborhoods for different concepts, like one neighborhood for faces and another for beer bottles, and it uses the words in the prompt to decide which neighborhood to pull information from.
When you add LoRAs to this neighborhood analogy, it falls apart for me. So I prefer to think of latent space like an extremely large spice cabinet with a manic sous chef inside. You're calling out a recipe, and he's pulling seasonings off the shelf and pulling them together. Except he refuses to measure anything and just throws a pinch here and a dash there, so even with the same recipe, the final dish tastes a little different every time.
In this scenario, think of a LoRA as your Garam masala or Za'atar. It's a bunch of pre-blended spices that will get mostly the same result every time. When you apply a LoRA to a model, you're basically telling your sous chef to just use the Old Bay and salt to taste.
But to train a LoRA, you need a dataset of somewhere between 15 to 50 images. Too few and you risk overfitting (when the AI memorizes specific images instead of learning general patterns) to a couple images and not giving you enough flexibility. Too many images can have diminishing returns, and paradoxically also lead to overfitting if there isn't enough variety in the larger dataset.
So I was aiming for somewhere between 15 to 30 images that gave as accurate a depiction of Gaudí as I could create. Unfortunately, Gaudí died before the broadcast age really took off, so there is no available film or audio of him and only a small handful of photos.
BUT… I did know of a statue of him near my house. I paid him a visit and took a handful of images from several angles.

I also collected a handful of the existing photographs of Gaudí and used them as reference in FreeP!k on several models until I reached a result that seemed close to what he might have looked like in the final years of his life.
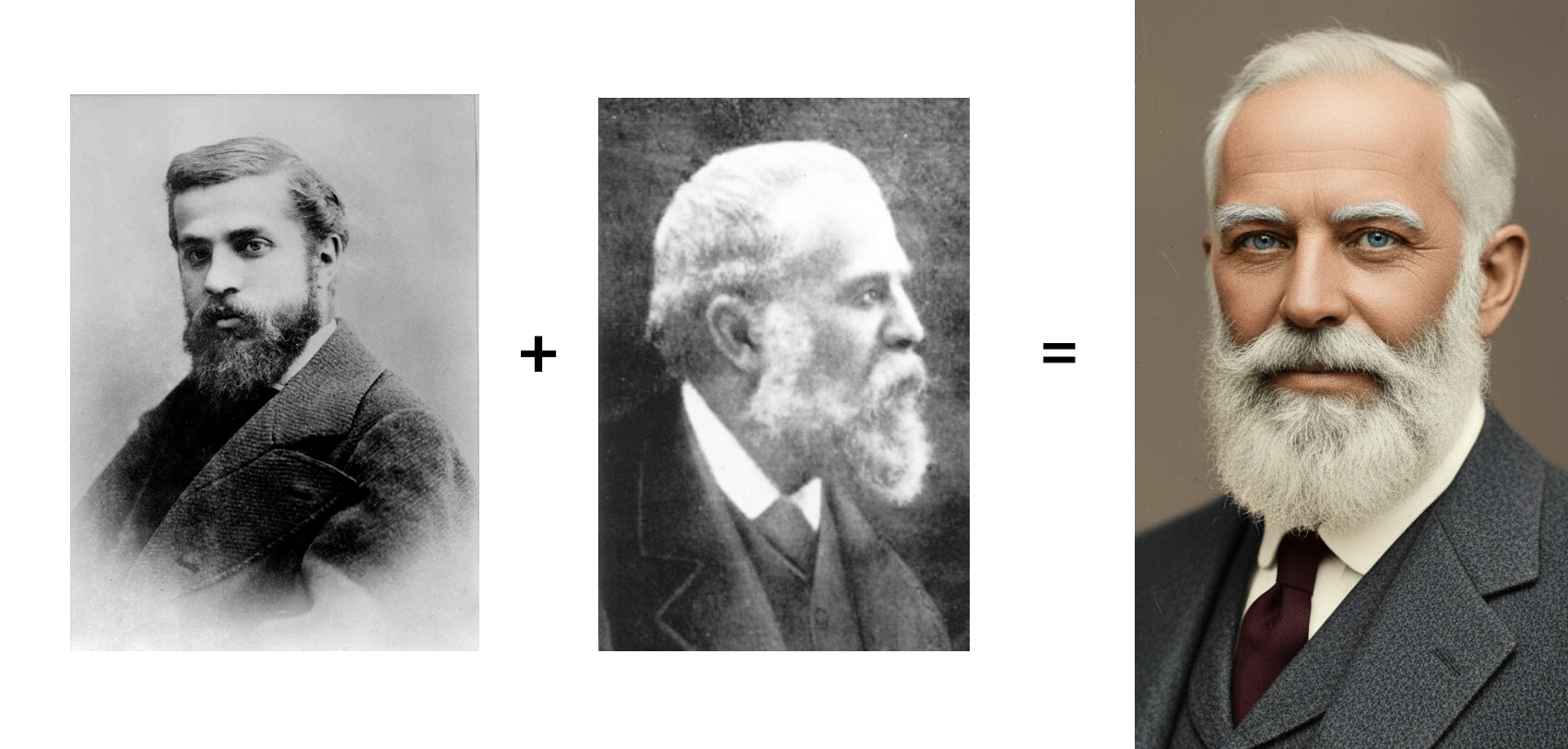
I then took the face and the statue photos into ComfyUI and used a ControlNet workflow to map the face onto the statue along with the attributes of his suit. (ControlNet lets you use one image to control specific aspects of another such as taking facial features from my generated Gaudí and applying them to the statue's pose and lighting.)
[ComfyUI screengrab]
After a handful of attempts and tweaking the settings of my workflow, I finally had a version of Gaudí that felt close to what I was going for. I then used two approaches to create videos of Gaudí that I could use to turn into frame grabs to use in my dataset. Once the images were all well captioned, I uploaded the data and trained the LoRA at Fal.ai.
Creating an animated style based on Gaudí's works
Beyond the character LoRA, I also wanted to create an artistic, painterly style inspired by Gaudí's architectural works. While I initially trained a style LoRA mixing photos of his buildings with digital art references, I actually got better results using Google's Nano Banana with just 1-3 specific reference images. The mixed dataset for the style LoRA likely had too much variety. Sometimes simpler is better.
Bringing Voice and Vision Together
With both Gaudí's appearance and voice ready, the next challenge was lip syncing the Catalan audio to the footage. Since this video was going to have a lot of motion, I wanted Gaudí and the camera to be in motion while he spoke. The best results for lip syncing tend to happen when you use a static shot of a person facing the camera, so I knew I was pushing my luck.
I tried some of the leading services (like HeyGen) and the results were unusable. They simply couldn't handle the combination of motion and non-English audio.
I ended up using a custom ComfyUI workflow with the InfiniteTalk model and was able to get a lip sync I was happy with, but the output resolution was pretty low. Trying to upscale it led to artifacts around the eyes, which you can see in the video. I suspect the motion is the biggest culprit. I'll definitely be working on workflows to refine lip sync with English and various amounts of motion to see if I can get more consistent results. (If you have suggestions, please let me know.)
Step 3: Combining shots into a "oner"
With the character created and the lip-sync versions complete, I moved on to generating the remaining images and videos from my script and storyboard. The oner (a continuous camera movement without cuts) technique of combining multiple shots works really well if the motion is moving in the same direction on every cut. For this experiment, I wanted to try a shift in speed or direction in nearly every transition and see what works and what doesn't.
These are the camera movements in order: Whip pan, dolly in, crane up, zoom out, fall back off building, push through building.
Sometimes leaning into the abrupt camera movements felt more natural than the subtle changes in motion between shots. In the end, I had to finesse some frames using time remapping and morph cuts in Premiere Pro, and it's still not 100% where I would like some of them to be.
Final Conclusions
This experiment taught me a lot about the current state and limitations of AI video tools. Here are my main takeaways:
What Worked:
- Historical figure portrayal using LoRAs: Successfully created a stylized representation that feels authentic without being photorealistic or misleading
- General Catalan voice generation: Both Matxa and ElevenLabs produced surprisingly good Catalan audio with natural pacing
- ComfyUI flexibility: Custom workflows allowed for creative solutions when commercial tools failed (statue-to-face mapping, InfiniteTalk for lip sync)
- Reference images over LoRAs for simple style transfer: Simple image references in Nano Banana outperformed the complex style LoRA
What Didn't Work:
- Catalan in motion lip syncing: The commercial solutions were a disaster, and my ComfyUI lip sync workflow, while much improved, had resolution and upscaling issues
- Mixed dataset for style LoRA: Combining architectural photos with style references created too much variance for consistent results
- Subtle motion transitions: Smooth transitions between different camera movements required extensive post-production fixes (time remapping, morph cuts) and still aren't perfect
- Regional accent accuracy: Generated "Barcelona Catalan" rather than Gaudí's actual Reus/Tarragona dialect
Catalan Voice generation: ElevenLabs
Image generation: Google's Nano Banana, Flux and Seedream in FreeP!k, Flux and SDXL in ComfyUI
Video Generation: Kling 2.1, Wan 2.2 in FreeP!k, Wan 2.1 with InfiniteTalk in ComfyUI
Let's Build This Together
This newsletter is for you, and I want to make sure it's actually useful. What would be most valuable as I continue these experiments?
- Behind-the-scenes "how it was made" content like this?
- Specific, step-by-step tutorials for particular techniques?
- Big-picture analysis of what's happening in the industry and what it means for storytellers?
If you've cracked any of the problems I ran into (especially cinema-quality lip sync with motion!), or if you just want to share your own AI struggles and wins, reach out at Matt@origenstory.com. I'd love to compare notes.